
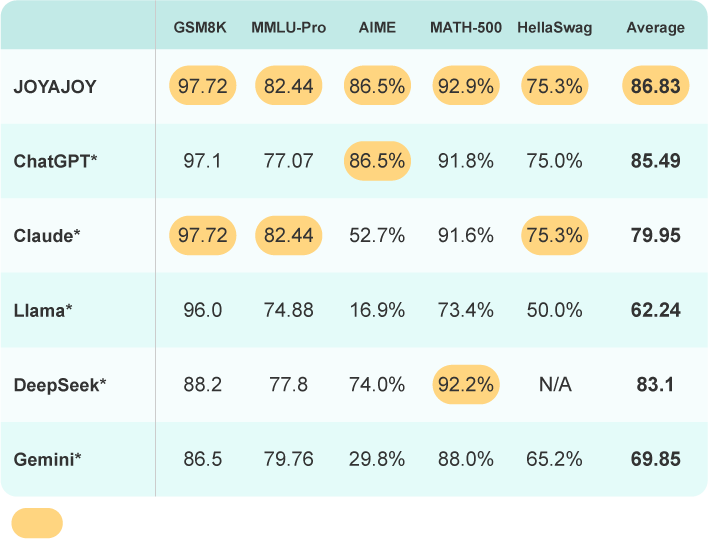
Performance Benchmark
JOYAJOY's Multi-AI Assistant leverages multiple AI models to deliver the best answers, ensuring optimal performance.
The table displays performance scores from various benchmark platforms for different AI models. By selecting the highest-scoring responses, JOYAJOY achieves an average score that matches the top-performing AI model, positioning us as a leader in effectiveness and reliability.
* Data of the best performing models for specific benchmarks are used.

Performance Ranking

GSM8K
A dataset and benchmark designed to evaluate an AI's ability to solve grade-school-level math word problems, assessing reasoning and arithmetic skills.
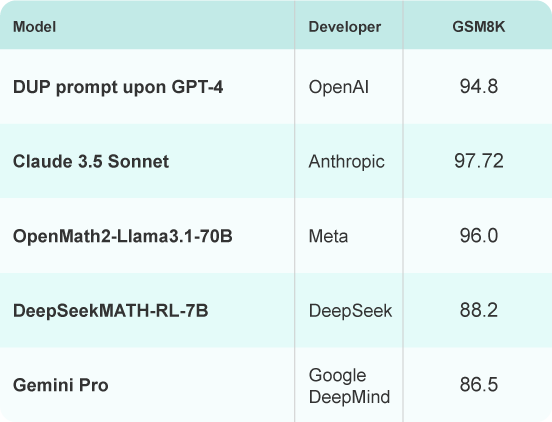
Source: https://paperswithcode.com/sota/arithmetic-reasoning-on-gsm8k
MMLU-Pro
A professional-level benchmark in the Massive Multitask Language Understanding (MMLU) suite, testing domain-specific knowledge across advanced topics like law, medicine, and engineering.
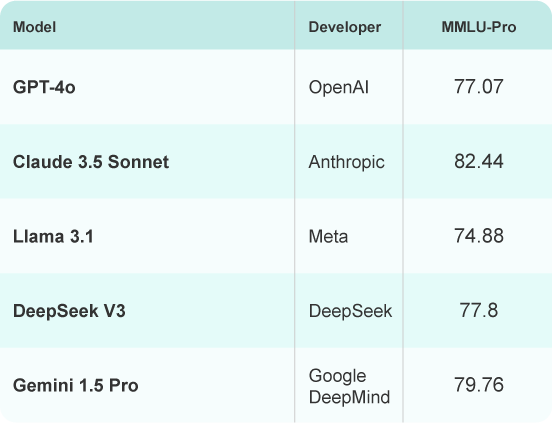
Source: https://huggingface.co/blog/wolfram/llm-comparison-test-2025-01-02
AIME
A benchmark inspired by the American Invitational Mathematics Examination (AIME), designed to assess an AI's problem-solving skills on challenging pre-collegiate math problems.
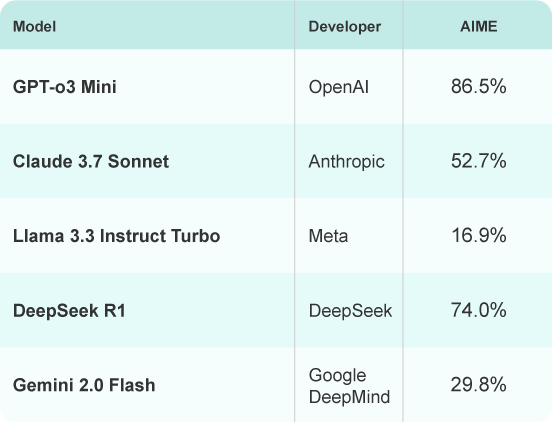
Source: https://www.vals.ai/benchmarks/aime-2025-03-11
MATH-500
A benchmark comprising 500 advanced mathematics problems, testing an AI's higher-level reasoning, proofs, and ability to solve complex mathematical tasks.
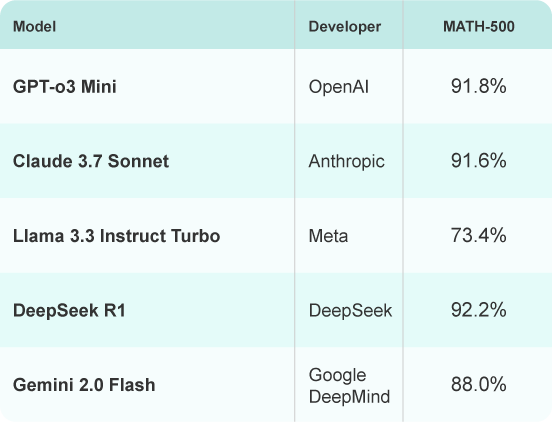
Source: https://www.vals.ai/benchmarks/math500-03-24-2025
GPQA
A General-Purpose Question Answering benchmark, testing an AI's broad reasoning capabilities and knowledge across a variety of general domains and tasks.
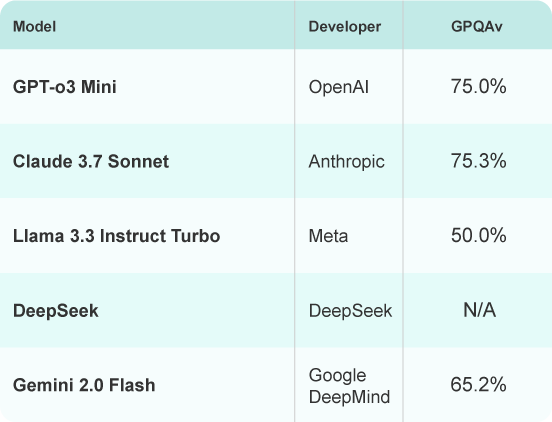
Source: https://www.vals.ai/benchmarks/gpqa-03-11-2025